求助求个算法
功能说明:本程序是一个基于易语言开发的桌面数据处理工具,主要用于对包含特定格式信息的文本数据进行自动解析、统计频次并生成结构化报告。程序依赖于"EDataStructure"支持库,利用其提供的数据结构功能来辅助完成数据去重和聚合操作。
一、程序功能概述
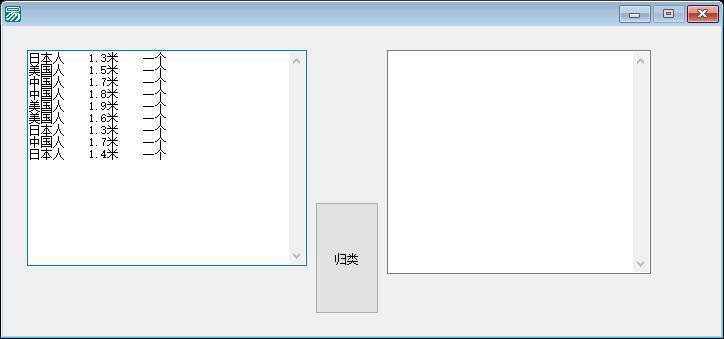
该程序的核心功能是“数据统计与整理”。它允许用户通过界面输入一段非结构化的文本数据(通常包含多行记录),程序会自动识别每行数据中的关键字段(根据变量命名推测为“国籍”和“身高”),计算出不同国籍下各个身高的出现次数,并以分组列表的形式展示在输出框中。这实际上是一个简易的二维数据频次统计器。
二、主要界面组件与交互
程序的交互主要通过以下几个界面元素完成:
1. 编辑框1(输入区):用户在此区域粘贴或输入待处理的原始文本数据。数据格式通常为多行文本,每行代表一条记录,字段之间通过空格分隔。
2. 按钮1(触发器):当用户完成数据输入后,单击此按钮触发 `_按钮1_被单击` 事件,开始执行数据统计逻辑。
3. 编辑框2(输出区):用于显示处理后的统计结果。内容包括唯一的国家列表,以及每个国家下对应的身高数据和该身高出现的频次。
三、核心逻辑流程分析
程序的执行流程可以分为数据预处理、去重提取、频次统计和结果格式化输出四个阶段:
1. 数据预处理与分割:
程序首先清空输出编辑框。接着读取编辑框1的内容,以换行符为界将其分割成多个字符串,存入 `分割文本_数组_h`。随后,程序进入第一个循环,遍历每一行数据,再次以空格为界将单行内容分割成更小的部分,存入 `分割文本_数组_l`。代码中包含判断条件 `取数组成员数 (分割文本_数组_l) ≥ 3`,这表明每条有效记录至少应包含三个部分(可能是前缀、国籍、身高或其他组合),以确保数据的完整性。
2. 唯一性提取(去重):
为了高效统计,程序利用了支持库中的数据结构节点对象(变量命名为 `国籍_节点` 和 `国籍_身高_节点`)。在遍历每一行时,程序会将提取到的“国籍”信息作为键值加入 `国籍_节点 `,将“国籍 + 身高”的组合字符串作为键值加入 `国籍_身高_节点`。利用数据结构存储属性的特性,这些节点自动实现了去重功能,确保后续统计的是唯一的国家和唯一的国籍身高组合。循环结束后,程序从这两个节点中分别取出所有的属性名(即唯一的国家和唯一的组合),存入 `国籍_数组` 和 `国籍_身高_数组`。
3. 频次统计:
程序初始化了一个整数数组 `国籍_身高_数量_数组`,大小与唯一的身高组合数一致,用于存放计数。随后,程序进行了第二轮遍历,这次是双重循环:外层遍历原始的所有数据行,内层遍历所有唯一的“国籍 + 身高”组合。如果某一行数据的组合匹配上某个唯一组合,则将该组合对应的计数器加 1。这一步完成了从原始文本到具体数字频次的映射。
4. 结果格式化输出:
最后,程序进入第三阶段的循环进行输出展示。外层循环遍历每一个唯一的“国籍”,先将国籍名称写入编辑框2。内层循环遍历所有唯一的“国籍 + 身高”组合,判断该组合是否属于当前的国籍(通过文本寻找功能实现)。如果匹配,则移除组合字符串中的国籍部分(仅保留身高),并在其后附加统计到的频次数量和换行符,最终拼接成美观的清单形式展示给用户。
四、技术特点与适用场景
1. 技术特点:
- 使用了易语言专用的数据结构库(EDataStructure),体现了利用第三方模块增强基础功能的编程思路。
- 采用了“先采集唯一键,后统计频次”的两步法算法,避免了在大量重复数据中频繁比较的低效操作。
- 具备一定的容错性,通过检查数组成员数来判断数据行的有效性,防止空行或格式错误导致程序崩溃。
- 输出部分使用了字符串替换和查找函数,使得最终展示的报表更加直观,易于阅读。
2. 适用场景:
- 人力资源部门快速统计员工身高分布情况。
- 人口普查数据的初步清洗与分布概览。
- 任何需要从杂乱的日志或文本文件中提取特定属性组合及其频率的轻量级需求。
五、总结
综上所述,这段易语言代码编写了一个实用的小型数据查询工具。它解决了从非标准格式的文本中提取关键属性并进行分类计数的痛点。尽管代码量不大,但逻辑清晰,涵盖了输入、解析、计算、输出的完整数据处理闭环。对于需要进行简单数据透视表生成的用户来说,这是一个高效的解决方案。

======窗口程序集1
| |
| |------ _按钮1_被单击
======窗口程序集1
| |
| |------ _按钮1_被单击
注:本站源码主要来源于网络收集。如有侵犯您的利益,请联系我们,我们将及时删除!
部分源码可能含有危险代码,(如关机、格式化磁盘等),请看清代码在运行。
由此产生的一切后果本站均不负责。源码仅用于学习使用,如需运用到商业场景请咨询原作者。
使用本站源码开发的产品均与本站无任何关系,请大家遵守国家相关法律。