
问题正则表达式的问题
功能说明:该程序是使用易语言(EPL)开发的桌面应用程序,主要功能是通过正则表达式对文本数据进行提取、筛选、清洗及格式化整理。程序依赖“RegEx”支持库来实现复杂的模式匹配功能,并采用了标准的图形用户界面(GUI),包含编辑框、列表框及按钮控件。以下是该程序的功能详细总结:
一、程序架构与基础组件
1. 开发环境:易语言版本 2,使用了正则表达式支持库(RegEx),表明程序核心逻辑依赖于文本模式的精确匹配。
2. 界面元素:虽然代码片段未展示窗体设计图,但从子程序和变量引用可知,界面至少包含两个多行编辑框(编辑框 1、编辑框 2)、一个列表框(列表框 1)以及两个触发操作的按钮(按钮 1、按钮 2)。
3. 数据流向:程序通过按钮点击事件驱动数据处理流程,数据主要在编辑框之间流转,最终在列表框中展示整理后的结果。
二、主要功能模块详解
1. 第一阶段文本提取(按钮 1 功能)
当用户点击“按钮 1"时,触发子程序 `_按钮 1_被单击`,执行以下逻辑:
- 初始化正则对象:创建一个名为“正则”的正则表达式对象。
- 设定匹配模式:使用模式字符串 `"domain(.*?)6"`。此模式旨在查找以单词"domain"开头,中间包含任意字符(非贪婪匹配),并以数字"6"结尾的所有文本段。
- 执行搜索:在“编辑框 1"中输入的原始文本内容中搜索所有符合上述模式的目标字符串。
- 结果显示:将搜索到的第一个匹配项(索引为 1)的完整匹配文本提取出来,赋值给“编辑框 2"的内容。这表明按钮 1 的主要作用是从原始杂乱的文本中筛选出特定格式的"domain...6"型数据,并将其转移至第二处理区域。
2. 第二阶段数据处理与清洗(按钮 2 功能)
当用户点击“按钮 2"时,触发子程序 `_按钮 2_被单击`,对上一阶段提取或现有的文本进行深度处理:
- 二次正则匹配:创建一个新的正则表达式对象,使用模式 `"\n(.*?) "`。此模式意在查找由换行符引导,直到遇到空格为止的文本内容。它在“编辑框 2"的内容中搜索所有符合该模式的片段。
- 初步列出与记录:清空“编辑框 1"。然后遍历搜索结果数组,将每个匹配到的文本片段添加到“列表框 1"中显示,同时将这些片段追加写入到“编辑框 1"的内容中。这一步是为了临时聚合数据。
- 文本清洗操作:
- 去除空行:调用“删全部空”函数移除“编辑框 1"内容中的空行。
- 去除空格:使用“子文本替换”函数,将所有普通空格字符替换为空,实现去空格化处理。
- 边缘换行符修剪:通过逻辑判断检查文本的首尾是否包含换行符。如果末尾有两个换行符或开头有两个换行符,分别截取去掉它们,确保生成的文本块首尾干净。
- 最终列表生成:
- 将清洗后的文本按换行符分割成数组。
- 清空“列表框 1"中的初始条目。
- 重新遍历分割后的文本数组,将每一项单独作为一个项目加入“列表框 1"。这意味着最终的输出是一个纯净的、无多余空格和空行的项目列表。
三、程序应用场景推测
根据代码中使用的具体正则模式,该程序可能用于特定的数据清洗任务,例如:
- 网络日志分析:提取日志中包含特定标识(如 domain 结尾带 6)的域名或路径信息。
- 数据库记录整理:从复制出来的非结构化数据中提取关键 ID 或字段,并统一格式方便后续导入或查看。
- 文本预处理:作为爬虫或采集工具的辅助环节,负责过滤掉无关字符,只保留核心数据行。
四、总结
综上所述,这是一个典型的文本处理辅助工具。它利用易语言的可视化优势和正则表达的强大匹配能力,实现了从“原始文本定位特定模式”到“多步骤清洗标准化输出”的全流程自动化。其核心价值在于通过两次不同的正则匹配策略配合字符串处理算法(去空、截断、分割),将混乱的输入数据转化为整洁的列表数据,极大提高了人工整理文本的效率。
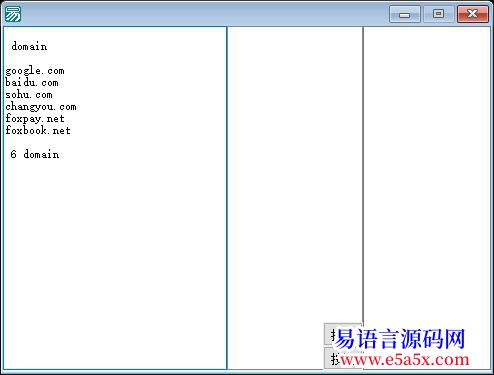
======窗口程序集1
| |
| |------ _按钮1_被单击
| |
| |------ _按钮2_被单击
注:本站源码主要来源于网络收集。如有侵犯您的利益,请联系我们,我们将及时删除!
部分源码可能含有危险代码,(如关机、格式化磁盘等),请看清代码在运行。
由此产生的一切后果本站均不负责。源码仅用于学习使用,如需运用到商业场景请咨询原作者。
使用本站源码开发的产品均与本站无任何关系,请大家遵守国家相关法律。